
Pengelompokan data menggunakan Algoritma Clustering telah menjadi fokus utama dalam dunia kecerdasan buatan . Algoritma Clustering, pada dasarnya, adalah cara untuk mengelompokkan sejumlah data menjadi kelompok-kelompok yang serupa berdasarkan pola tertentu. Ini menjadi semakin penting seiring dengan meningkatnya kompleksitas data yang dihasilkan oleh sistem modern.
Dalam memahami dasar-dasar algoritma clustering, kita dihadapkan pada tantangan untuk mengidentifikasi pola tersembunyi dalam data yang mungkin sulit terlihat mata telanjang. Inilah di mana kecerdasan buatan berperan sebagai pemimpin, memberikan kemampuan untuk mengenali pola dan relasi antar data secara otomatis. Memahami esensi algoritma clustering menjadi kunci untuk mengurai kerumitan data, membuka pintu bagi pemahaman lebih dalam tentang struktur dan hubungan di antara informasi yang tersedia.
Membuka Pintu Algoritma Clustering
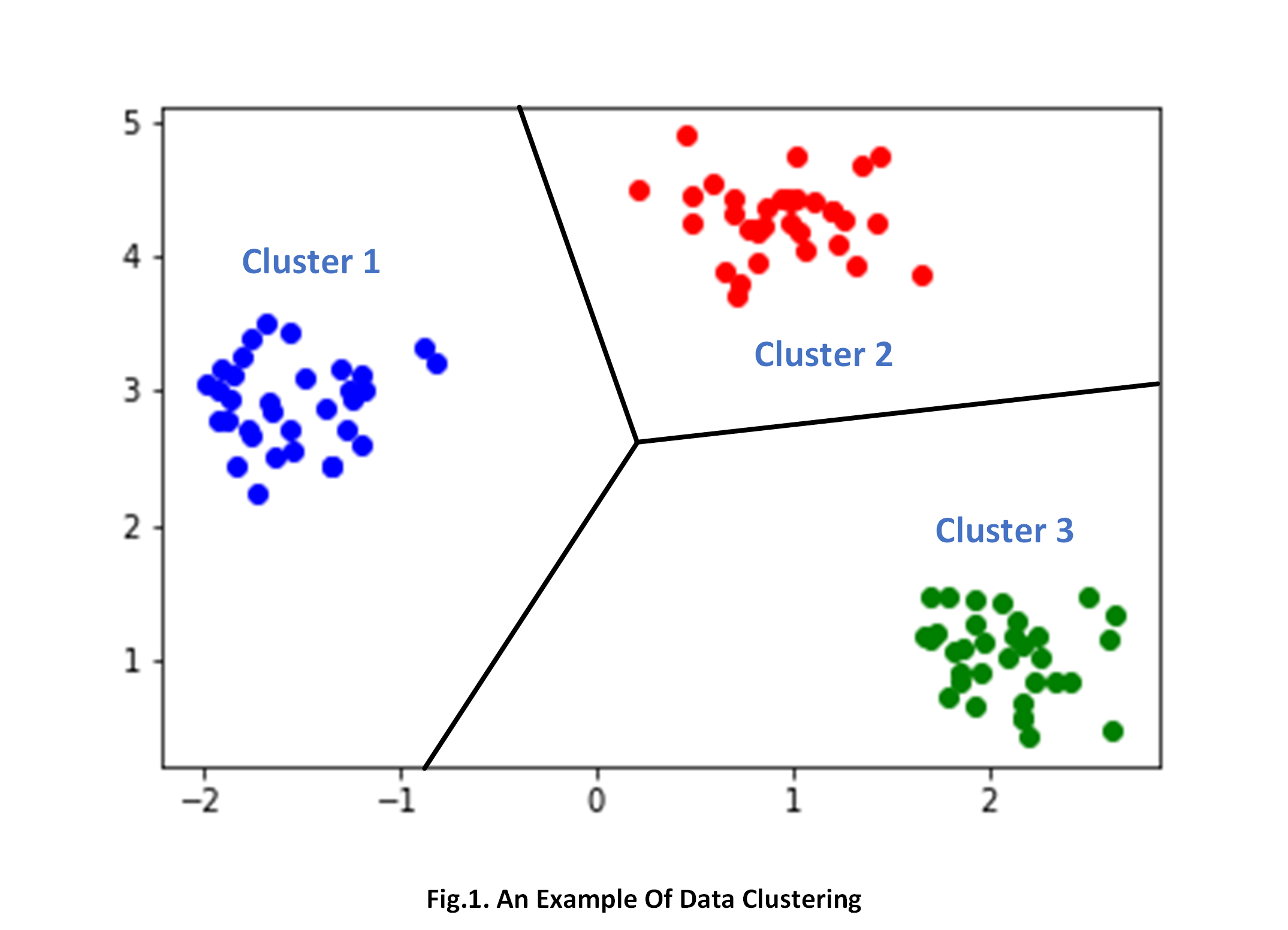
Algoritma Clustering menjadi kunci rahasia di balik kemampuan sistem kecerdasan buatan dalam mengelompokkan data. Terlepas dari istilah teknis yang terdengar kompleks, konsep dasar di balik clustering tidaklah sesulit yang mungkin terbayangkan. Mari kita jelajahi mengapa clustering memiliki peran penting dalam dunia pengelompokan data.
Mengapa Clustering Penting dalam Pengelompokan Data
Clustering, pada dasarnya, adalah kunci untuk merapikan kekacauan data. Dengan mengelompokkan data berdasarkan pola dan kesamaan tertentu, sistem dapat membaca dan memahami informasi dengan lebih efektif. Bayangkan seolah-olah data adalah sebuah kumpulan puzzle, dan clustering adalah cara kita menyusunnya agar gambar keseluruhan menjadi jelas. Tanpa clustering, data hanyalah kumpulan angka dan huruf tanpa makna yang sesungguhnya.
Dasar-Dasar Algoritma Clustering
Dalam menjelajahi dasar-dasar algoritma clustering, kita masuk ke dalam dunia rumit di mana komputer secara otomatis mengenali pola dalam data. Algoritma ini berfungsi seperti detektif pintar yang mengelompokkan bukti untuk menemukan solusi. Dengan pemahaman mendalam terhadap karakteristik algoritma, kita dapat memahami bagaimana AI mampu menemukan pola dalam dataset yang mungkin terabaikan oleh mata manusia.
Konsep Dasar Pengelompokan Data
Penting untuk memahami bahwa konsep pengelompokan data tidak terbatas pada dunia teknologi. Sehari-hari, kita secara alami melakukan pengelompokan saat mengorganisir buku di rak atau mengkategorikan kontak dalam ponsel. Algoritma clustering menerapkan prinsip yang sama, memungkinkan sistem untuk mengelola data dengan cara yang lebih manusiawi.
Tipe-Tipe Algoritma Clustering
Setiap algoritma clustering memiliki kepribadian unik, mirip berbagai jenis musik yang memenuhi selera kita. Dari k-means yang analitis hingga hierarki yang mirip struktur pohon, setiap tipe menghadirkan pendekatan yang berbeda dalam mengatasi tantangan pengelompokan data.
Perbandingan Algoritma Clustering Terkemuka
Sebagaimana kita memilih baju sesuai acara, pemilihan algoritma clustering juga memerlukan pertimbangan yang matang. Perbandingan antara kinerja algoritma menjadi penentu utama dalam memastikan keberhasilan proses clustering.
Langkah-langkah Implementasi Algoritma Clustering

Pemahaman Dataset Sebelum Implementasi
Sebelum kita membenamkan diri dalam keajaiban algoritma clustering, penting untuk memahami dataset yang akan kita olah. Dataset merupakan kumpulan data yang menjadi bahan bakar utama dalam proses clustering. Data yang kompleks atau tidak terstruktur membutuhkan pendekatan clustering yang berbeda dibandingkan dengan data yang terorganisir dengan baik.
Preprocessing Data untuk Algoritma Clustering
Seiring kita melangkah ke dalam implementasi algoritma clustering, tahapan preprocessing data menjadi pondasi utama. Membersihkan data dari pencilan, mengisi nilai yang hilang, dan mengubah format data menjadi langkah krusial sebelum menerapkan algoritma clustering. Preprocessing menciptakan fondasi yang kokoh untuk hasil clustering yang akurat dan relevan dengan kondisi sebenarnya.
Menentukan Jumlah Cluster yang Optimal
Menentukan jumlah cluster yang tepat adalah kunci utama keberhasilan algoritma clustering. Meskipun terdengar seperti tantangan yang kompleks, beberapa metode seperti elbow method atau silhouette score dapat membantu kita menemukan jumlah cluster yang optimal. Ini adalah langkah kritis untuk memastikan hasil clustering memberikan informasi yang signifikan dan mudah diinterpretasi.
Algoritma K-Means: Langkah-langkah dan Implementasi
Inisialisasi Pusat Cluster
Algoritma K-Means memulai perjalanannya inisialisasi acak dari pusat cluster. Langkah ini memastikan bahwa setiap titik data terasosiasi dengan cluster yang sesuai. Meskipun inisialisasi pusat cluster dapat mempengaruhi hasil akhir, algoritma melakukan iterasi untuk mencapai konvergensi.
Proses Iterasi hingga Konvergensi
Setelah inisialisasi, proses iterasi dimulai. Pada setiap iterasi, K-Means menghitung rata-rata titik data dalam setiap cluster dan memperbarui posisi pusat cluster. Iterasi terus berlanjut hingga pusat cluster stabil dan konvergensi tercapai. Hasil akhirnya adalah cluster yang optimal berdasarkan kedekatan titik data.
Evaluasi Hasil dan Penyempurnaan
Setelah algoritma berjalan, evaluasi hasil clustering menjadi tahap selanjutnya. Menganalisis kecocokan antara data asli dan hasil clustering membantu memahami sejauh mana algoritma berhasil. Jika perlu, langkah-langkah atau parameter dapat disesuaikan untuk meningkatkan kualitas clustering.
Algoritma Hierarki: Mendaki Pohon Pengelompokan
Algoritma clustering hierarki bekerja cara yang berbeda. Sebaliknya, ia menciptakan struktur pohon atau dendrogram yang merepresentasikan hierarki cluster. Dalam langkah pembentukan hierarki, titik data dikelompokkan berdasarkan kedekatan mereka.
Pembentukan Hierarki Cluster
Hierarki cluster terbentuk saat titik data digabungkan berdasarkan kedekatan. Dendrogram menjadi panduan visual yang membantu memahami struktur hierarki. Pilihan untuk memotong dendrogram menentukan jumlah cluster yang diinginkan.
Menentukan Pemotongan yang Tepat
Menentukan pemotongan yang tepat pada dendrogram adalah langkah krusial dalam algoritma clustering hierarki. Pemotongan ini menentukan jumlah cluster akhir. Menggunakan pemotongan yang bijak memastikan hasil clustering memberikan wawasan yang berguna dan mudah diinterpretasi.
Algoritma Clustering Dasar-dasar dalam Pengelompokan Data dengan AI

Tantangan dan Strategi dalam Algoritma Clustering
Clustering, dalam dunia pengelompokan data kecerdasan buatan, menantang dan membutuhkan strategi yang matang. Menggambarkan kompleksitas di balik upaya ini.
Tantangan Umum dalam Pengelompokan Data
Kita hadapi . Identifikasi pola dalam dataset besar bisa rumit karena variasi nilai, dimensi, dan tingkat kebisingan. Kesulitan menentukan jumlah cluster optimal seringkali menjadi masalah, membutuhkan kejelian dalam pemilihan metode yang sesuai.
Outlier dan Pengaruhnya pada Hasil Clustering
Melangkah lebih dalam, menjadi fokus. Outlier atau data yang tidak sesuai dapat memberikan dampak besar terhadap hasil clustering. Membedakan outlier dari pola umum dan mengelolanya dengan cermat diperlukan agar klaster yang dihasilkan lebih akurat.
Masalah Scalability pada Data Besar
Ketika berbicara tentang , kita menyadari bahwa semakin besar dataset, semakin kompleks pula perhitungan. Algoritma clustering yang efisien dan scalable menjadi keharusan untuk menangani jumlah data yang terus meningkat.
Strategi untuk Mengatasi Tantangan
Berbicara tentang , adaptabilitas dan responsif terhadap dinamika data sangat diperlukan. Penggunaan teknik reduksi dimensi atau sampling cerdas bisa menjadi solusi untuk meningkatkan efisiensi algoritma.
Penggunaan Metrik Evaluasi yang Tepat
Tidak bisa diabaikan. Menggunakan metrik evaluasi yang sesuai seperti Silhouette Score atau Dunn Index membantu mengukur kualitas klaster yang dihasilkan, memastikan hasil yang lebih informatif.
Pengoptimalan Parameter Algoritma
Penyetelan yang tepat dapat meningkatkan kinerja dan akurasi clustering.
Kasus Penggunaan Algoritma Clustering dalam Kehidupan Nyata
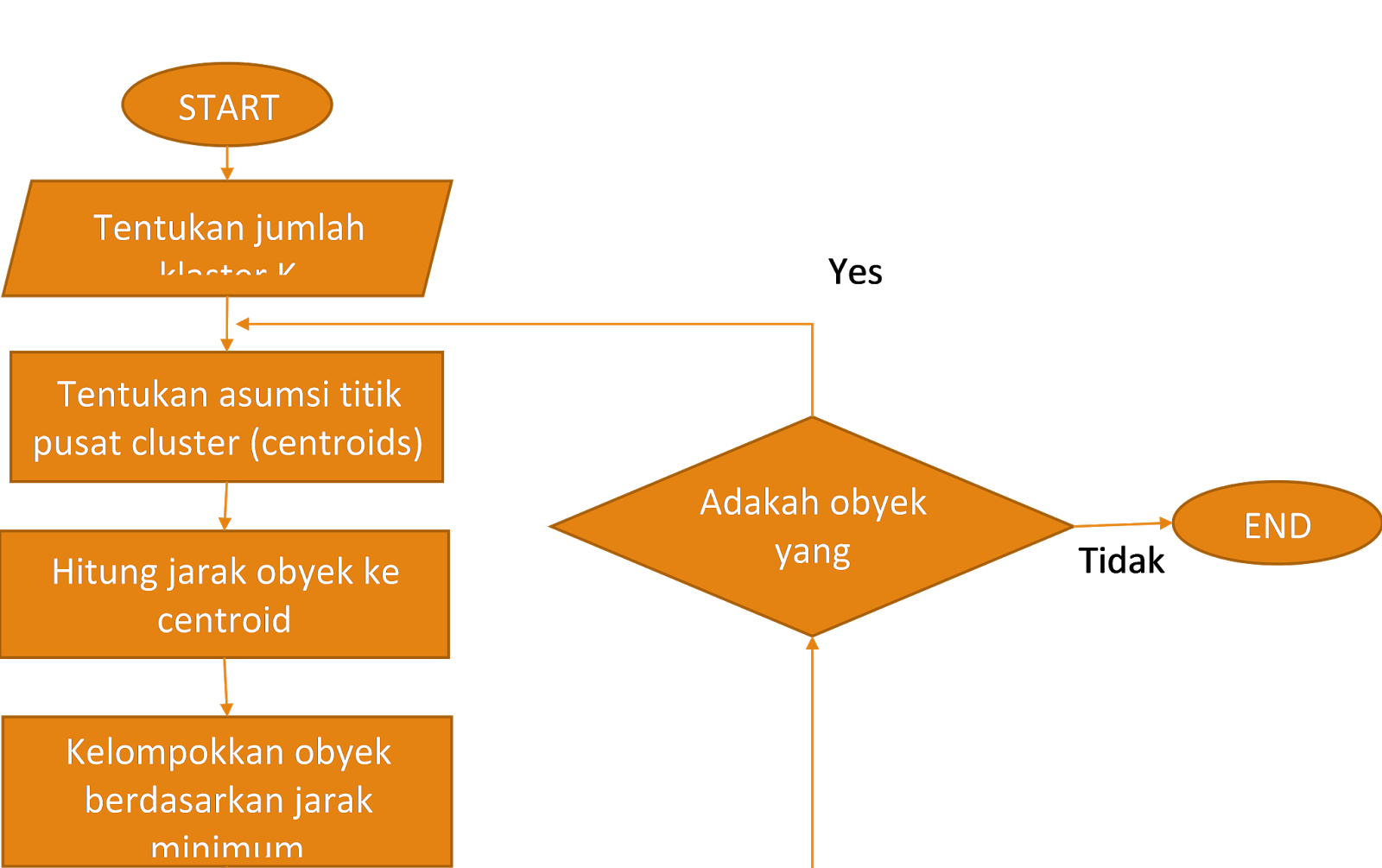
Algoritma Clustering, menjadi bagian integral dari dunia kecerdasan buatan , membuka pintu untuk pemahaman yang lebih baik terhadap data yang kompleks. Salah satu aplikasi nyata yang mengesankan adalah dalam meningkatkan layanan pelanggan. Dengan menggunakan algoritma clustering, perusahaan dapat menganalisis data pelanggan untuk memahami preferensi dan kebutuhan mereka.
Analisis Data Pelanggan untuk Peningkatan Layanan
Dalam penggunaan algoritma clustering pada analisis data pelanggan, perusahaan dapat mengidentifikasi kelompok pelanggan preferensi serupa. Misalnya, pelanggan yang cenderung membeli produk yang serupa atau memiliki kebutuhan layanan yang mirip dapat dikelompokkan bersama. Ini memungkinkan perusahaan untuk menyusun strategi pemasaran yang lebih terarah, menyajikan produk atau layanan yang lebih sesuai dengan kebutuhan masing-masing kelompok.
Implementasi K-Means pada Data Pelanggan
Salah satu algoritma clustering yang sering digunakan ini adalah K-Means. Dengan menerapkan K-Means pada data pelanggan, perusahaan dapat secara otomatis mengelompokkan pelanggan ke dalam segmen yang lebih homogen. Hal ini memudahkan perusahaan untuk menyesuaikan strategi layanan, meningkatkan kepuasan pelanggan, dan pada gilirannya, mendongkrak loyalitas pelanggan.
Manfaat dan Kesimpulan dari Analisis
Manfaat dari analisis data pelanggan algoritma clustering tidak hanya terbatas pada aspek pemasaran. Perusahaan juga dapat merancang program loyalitas yang lebih efektif, meningkatkan efisiensi operasional, dan memperkuat hubungan dengan pelanggan. Penggunaan algoritma clustering dalam analisis data pelanggan bukan hanya sebuah inovasi, melainkan investasi cerdas untuk pertumbuhan bisnis yang berkelanjutan.
Aplikasi Algoritma Clustering dalam Bidang Kesehatan
Algoritma clustering juga memberikan kontribusi signifikan dalam bidang kesehatan, terutama dalam personalisasi pengobatan.
Pengelompokan Pasien untuk Personalisasi Pengobatan
Menganalisis data kesehatan pasien menggunakan algoritma clustering, dokter dapat mengelompokkan pasien diagnosis atau profil kesehatan serupa. Ini memungkinkan personalisasi pengobatan yang lebih akurat, dengan mempertimbangkan respons unik setiap kelompok pasien terhadap terapi tertentu. Hal ini membuka jalan bagi peningkatan hasil pengobatan dan pengurangan risiko efek samping.
Dampak Positif pada Sistem Kesehatan
Penerapan algoritma clustering dalam kesehatan tidak hanya bermanfaat untuk pasien secara individu, tetapi juga memberikan dampak positif pada sistem kesehatan secara keseluruhan. Dengan mengoptimalkan penggunaan sumber daya, mengurangi waktu diagnosa, dan meningkatkan efektivitas pengobatan, algoritma clustering membantu menciptakan sistem kesehatan yang lebih efisien dan responsif.



